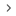

2025年6月23日-6月28日,软件工程领域顶会The ACM International Conference on the Foundations of Software Engineering(FSE 2025)和The ACM SIGSOFT International Symposium on Software Testing and Analysis(ISSTA 2025)同时在挪威特隆赫姆成功举办。浙江大学软件工程团队两篇论文分别荣获FSE 2025杰出论文奖(ACM SIGSOFT Distinguished Paper Award)和ISSTA 2025杰出论文奖(ACM SIGSOFT Distinguished Paper Award)。获奖的两项研究成果分别为“Less is More: On the Importance of Data Quality for Unit Test Generation”和“LLM4SZZ: Enhancing SZZ Algorithm with Context-Enhanced Assessment on Large Language Models”。FSE 2025会议共收到来自全球的612篇论文投稿,最终录用135篇论文。ISSTA 2025会议共收到来自全球的550篇论文投稿,最终录用107篇论文。
以下为获奖论文奖状与颁奖留影。
FSE 2025获奖证书

ISSTA 2025获奖证书


FSE 2025会议颁奖现场
(左三为浙江大学求是特聘教授夏鑫老师,左四为浙江大学胡星老师)

ISSTA 2025会议颁奖现场
(左二为浙江大学学生唐凌霄,左三为浙江大学鲍凌峰老师,左四为浙江大学刘忠鑫老师)
会议介绍
The ACM International Conference on the Foundations of Software Engineering (FSE)是软件工程领域的顶级学术会议,也是中国计算机学会(CCF)推荐的A类国际会议,截止2025年已举办33届。作为软件工程领域的顶级学术会议之一,FSE是软件工程领域研究人员、教育从业人员和工业界人士介绍与讨论领域最新思想,创新成果,研究趋势和分享经验的重要论坛之一,长期代表着全球软件工程研究的前沿方向,汇聚了来自学术界与工业界的众多顶尖研究人员和实践专家。FSE 2025共收到612篇论文投稿,最终录用135篇,录用率为22.06%。
The ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA) 是软件工程领域的顶级学术会议,专注于软件测试与分析方向,同时也是中国计算机学会(CCF)推荐的A类国际会议,截止2025年已举办34届。作为软件测试与分析领域的旗舰会议,ISSTA为全球来自学术界、工业界的研究人员、教育工作者和实践专家提供了一个卓越的论坛,以展示和讨论该领域最新的思想、创新成果、研究趋势及分享实践经验。ISSTA长期引领着全球软件测试与分析研究的前沿,是该领域内最重要和最具影响力的学术盛会之一。ISSTA 2025共收到550篇论文投稿,最终107录用篇,录用率为19.9%。
论文介绍:
研究成果一:Less is More: On the Importance of Data Quality for Unit Test Generation
近期研究提出利用大语言模型自动化生成单元测试代码,然而,关于测试生成数据集质量的研究却未受到关注。为了弥补这一空白,该论文研究了噪声数据对基于大模型的测试生成模型性能的影响,并提出了一种自动化噪声数据过滤框架CleanTest。该论文分析总结出八种不同类型的噪声数据,并邀请多位测试领域专家验证和评估噪声数据分类法的重要性、合理性和正确性。在噪声数据类型分析的基础上,提出了一个噪声数据过滤框架CleanTest,并检测现有测试生成数据集中的噪声数据分布。结果表明,现有数据集中包含大量的噪声数据。此外,该论文还发现过滤噪声数据可以提升大模型生成测试代码的分支覆盖率和检测到的软件缺陷数量,微调模型时间平均减少了17.5%。
研究方法概述图
本文的第一作者为博士四年级学生张峻伟,通讯作者为胡星副教授。此项研究成果由浙大、华为和新加坡管理大学合作完成。论文原文:https://dl.acm.org/doi/10.1145/3715778。
研究成果二:LLM4SZZ: Enhancing SZZ Algorithm with Context-Enhanced Assessment on Large Language Models
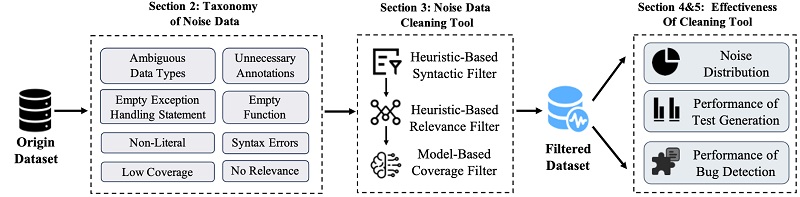
SZZ算法是定位引入软件缺陷代码提交的主流技术,但现有变体或依赖启发式规则导致性能有限,或基于深度学习但实现复杂且牺牲召回率。为解决这些问题,该论文提出了一种利用大语言模型(LLM)的新方法LLM4SZZ 。其核心是一种自适应策略,该方法首先通过“上下文增强评估”阶段判断LLM能否真正理解一个特定缺陷,若模型能理解,则采用“上下文增强识别”方法精确找出缺陷提交;反之,则回退到“基于排名的识别”方法对可疑代码进行排序。经三个由开发者标注的高质量数据集验证,LLM4SZZ的性能全面优于所有基线方法,并能额外识别出基线方法普遍遗漏的缺陷提交。
研究方法概述图
 友情链接
友情链接